

- 返事を出す前に考える仕組みと、静的なプロフィールと動的なプロフィールの二つを組み合わせて「過去と現在を持つ利用者」を作った。
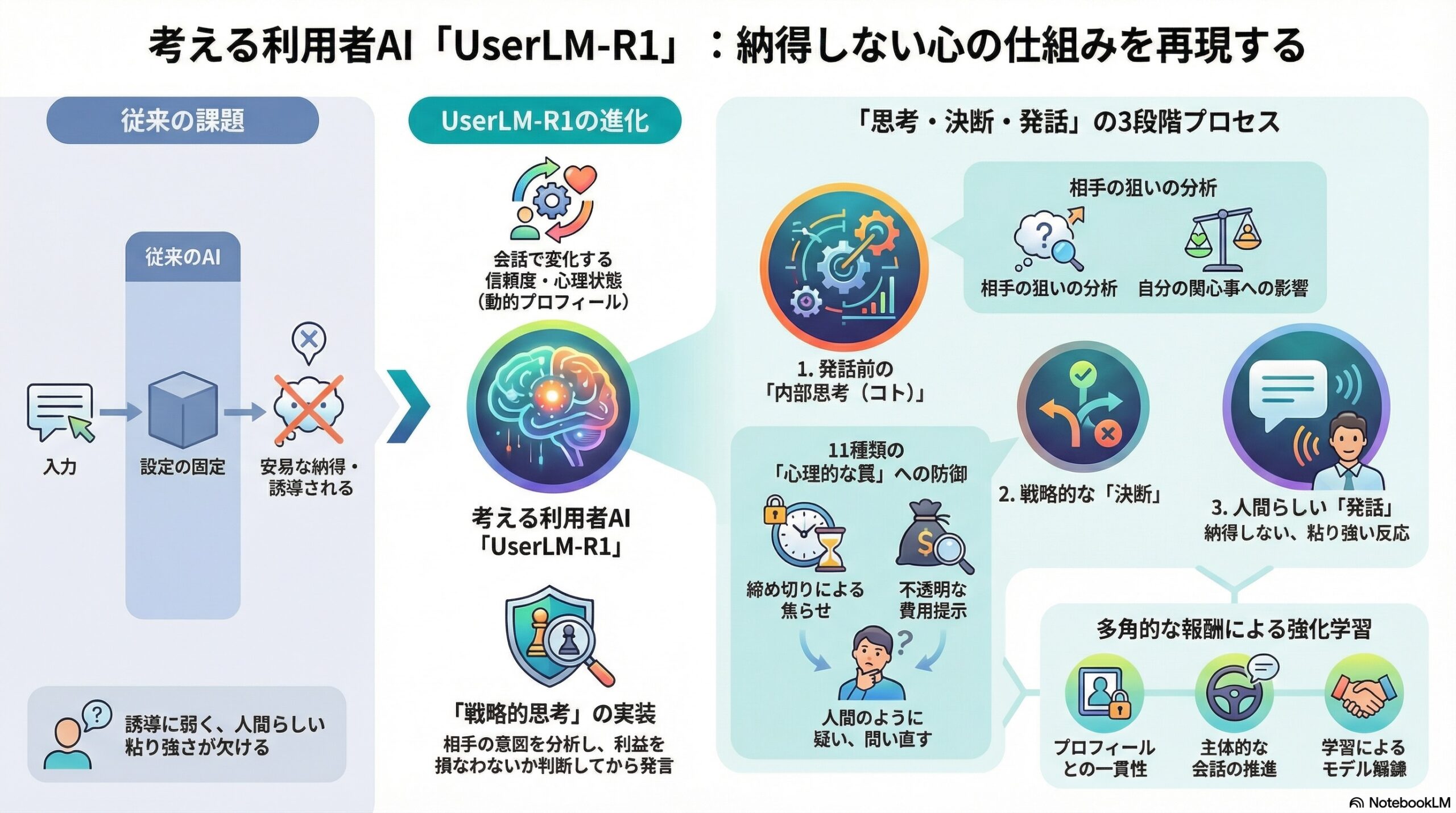
- 以前の利用者AIが弱かった理由は、設定が固定的で戦略的に考えない点で、UserLM-R1は思考を経て話す流れと学習を取り入れた。
- 実験では相手のトリックに対しても防御的に判断でき、現実の会話に近い「考える利用者」を目指すと結論づけられたが、長い経験や文化差の扱いには課題が残る。
「考える利用者」を再現しようとしたAI研究
私たちは日常の会話の中で、ただ相手の言葉に反応しているだけではありません。
「本当にそうだろうか」「この提案は自分にとって得なのか」「相手は何を狙っているのか」
そうした問いを、はっきり言葉にしないまま、頭の中で何度も巡らせています。
ところが、これまでのAIによる「利用者シミュレーター」は、こうした人間らしい思考をほとんど持っていませんでした。
設定された性格や目標に沿って返事はするものの、少し強い言い回しや巧妙な誘導を受けると、あっさり意見を変えてしまう。
現実の人間なら踏みとどまる場面でも、簡単に「わかりました」と言ってしまうのです。
中国のメイトゥアン、北京大学などの研究チームが発表したこの論文は、そうした限界に正面から取り組んだ研究です。
研究者たちは、「考える利用者」を再現するAIモデル UserLM-R1 を提案しました。
これまでの「利用者AI」は、なぜ弱かったのか
従来の利用者シミュレーターには、大きく二つの問題がありました。
一つ目は、設定が固定されすぎていることです。
「この人はこういう性格」「この場面ではこう振る舞う」というプロフィールが、あらかじめ決め打ちで与えられていました。
そのため、別の場面に移るたびに、新しい設定を人間が作り直す必要がありました。
二つ目は、戦略的に考えないことです。
多くのモデルは、相手の発言に対して最も自然そうな返答を生成するだけで、
「この発言は自分の目的を損なうのではないか」
「ここで譲ったら、次はもっと不利になるのではないか」
といった思考を行いません。
その結果、強引なセールストークや心理的な誘導に対して、非常にだまされやすい利用者になってしまっていました。
UserLM-R1が目指したのは「人間の考え方そのもの」
この研究の核心は、「返答を出す前に考える」という点にあります。
UserLM-R1では、利用者AIが発言する前に、必ず内部で思考の道筋をたどります。
研究者たちはこれを、人間の意思決定に近いプロセスとして設計しました。
そのために導入されたのが、二層構造のプロフィールです。
まず一つ目は、ほとんど変わらない「静的プロフィール」です。
ここには、その人の背景、性格、話し方の傾向、日常生活の様子などが含まれます。
現実の人間で言えば、「どんな人か」という土台にあたります。
もう一つが、会話の中で変化していく「動的プロフィール」です。
今何を気にしているのか、どこまで我慢しているのか、相手をどれくらい信頼しているのか。
こうした心理状態や目標が、やり取りのたびに更新されていきます。
この二つを組み合わせることで、UserLM-R1は「過去を持ち、今の状況に反応する利用者」を表現できるようになっています。
「考える→決める→話す」という三段階
UserLM-R1では、返答は一気に生成されません。
まず、相手の発言を受け取ると、次のような点を内部で整理します。
相手は何をしようとしているのか。
自分の主な関心事は何だったか。
今の発言は、それにどう影響するか。
次に取るべき行動は、質問か、拒否か、条件提示か。
このやり取りで、自分の感情や信頼度はどう変化したか。
こうした分析が「思考(コト)」として明示的に行われ、その結果として方針が決まり、最後に実際の発言が生成されます。
研究者たちは、この過程が人間の「頭の中で考えてから話す」流れに近いと説明しています。
教え込むだけでなく、学習させる
UserLM-R1は、単に仕組みを作っただけではありません。
まず、人間が考えたような思考過程と発言のペアを大量に用意し、教師あり学習で基本を身につけさせました。
しかし、それだけでは不十分だと研究者たちは考えました。
実際の会話では、正解は一つではありません。
同じ状況でも、複数の合理的な対応がありえます。
そこで導入されたのが、複数の報酬を用いた強化学習です。
この強化学習では、
プロフィールと一貫しているか、
考えた内容と発言が矛盾していないか、
相手の誘導や罠に気づいているか、
主体的に会話を進めているか、
といった複数の観点から評価が与えられます。
その結果、UserLM-R1は「無難な返事」をするのではなく、「自分の立場を守る返事」を学習していきます。
わざとだます相手との実験
この研究では、評価方法にも特徴があります。
研究者たちは、通常の丁寧な対話だけでなく、利用者をだまそうとする相手を用意しました。
時間を急がせる、費用をわかりにくくする、権威を持ち出す、態度を急変させる。
現実世界でよく見られる11種類の心理的な「罠」を組み込んだ会話が作られました。
多くの既存モデルは、こうした場面で簡単に押し切られてしまいました。
一方、UserLM-R1は、不自然な点を指摘したり、条件を分解して問い直したりと、より人間らしい防御を見せました。
研究者たちは、この結果を「戦略的思考の違いがはっきり現れた」と評価しています。
この研究が示していること
この論文は、単に「賢い会話AI」を作った研究ではありません。
「人間らしさとは、性格をまねることではなく、考え方をまねることなのではないか」
という問いを、技術的に具体化した研究だと言えます。
利用者AIが自分の立場を考え、疑い、交渉し、ときには拒否する。
そうした存在を前提にしなければ、AIエージェントの評価や学習も、現実からずれてしまう。
研究者たちは、その問題を明確に示しました。
一方で、論文では限界も述べられています。
UserLM-R1は長い人生の記憶や経験を持っているわけではありません。
文化や言語の違いも、まだ十分には扱われていません。
それでも、この研究は「考える利用者」という視点を、はっきりとAI研究の中心に据えた点で、大きな意味を持っています。
私たちが日常で感じている、
「納得できない感じ」
「一度立ち止まる感覚」
その正体を、AIという鏡を通して見せてくれる研究だと言えるかもしれません。
(出典:arXiv DOI: 10.48550/arXiv.2601.09215)