- ARC(CogARC)では少ない例から抽象ルールを推測し、思考の軌跡や編集行動が記録された。
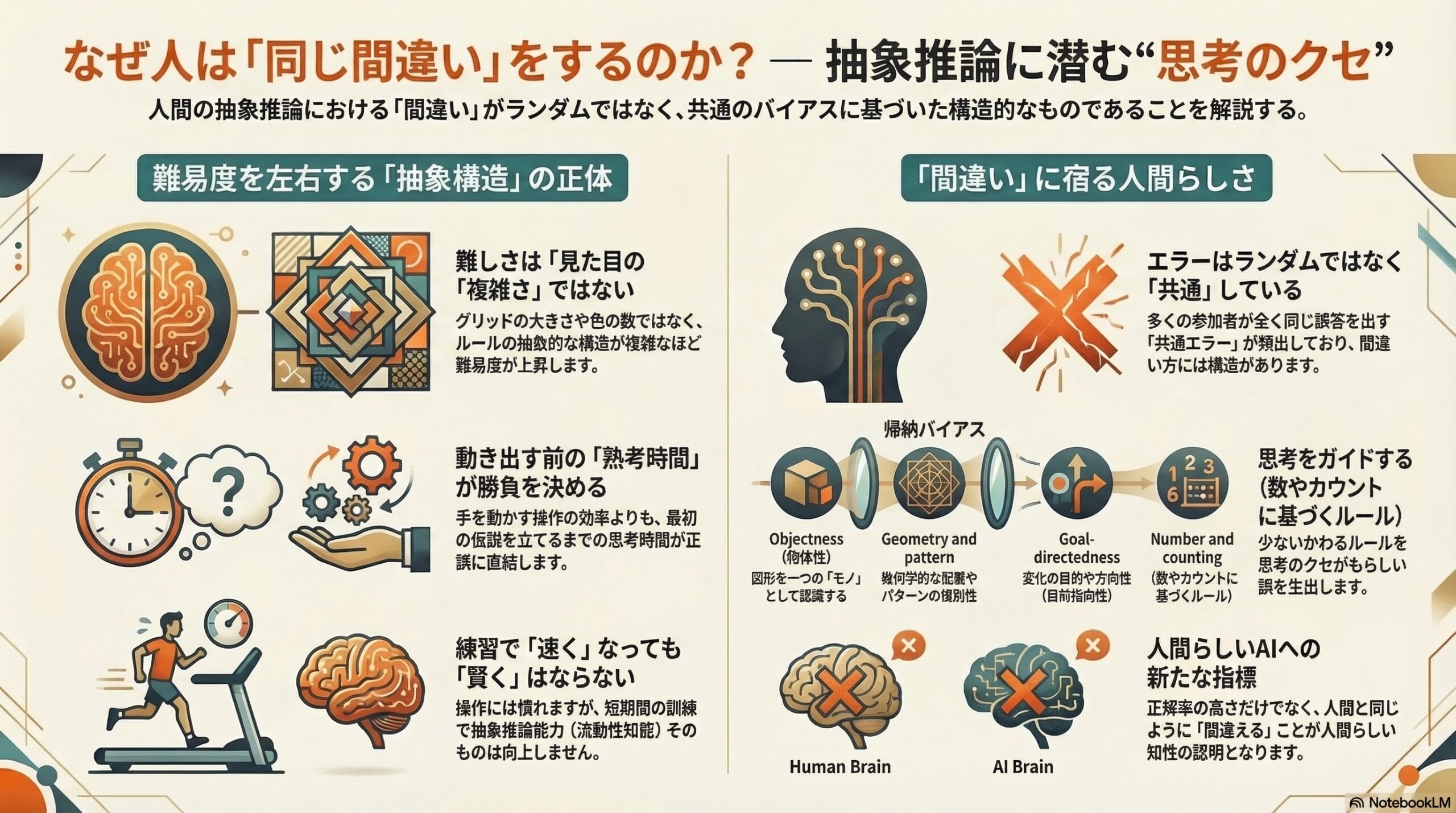
- 難しい問題ほど熟考時間が長く、難易度は抽象構造の複雑さに左右され、見た目の複雑さは関係が薄い。
- 成績の向上にはならず、間違いは似たパターンで繰り返される帰納バイアスが影響するという発見がある。
私たちは、ほんの少しの手がかりから「ルール」を見つけ出します。
数枚の図を見ただけで、そこに潜む規則を推測し、新しい問題にも当てはめることができます。
けれど、そのとき私たちは本当に「自由に」考えているのでしょうか。
それとも、目には見えない“思考のクセ”に導かれているのでしょうか。
今回紹介する研究は、この問いを真正面から扱っています。
研究を行ったのは、ボストン大学の Graduate Program for Neuroscience、Department of Psychological and Brain Sciences、Center for Systems Neuroscience、Cognitive Neuroimaging Center に所属する研究チームです。彼らは、人間がどのように抽象ルールを推論し、どのように誤るのかを、大規模な行動データから詳細に分析しました。
「ARC」という抽象推論課題
研究で用いられたのは、「ARC(Abstraction and Reasoning Corpus)」という抽象視覚推論課題です。
参加者は、いくつかの入力図と出力図の例を見せられます。
その変換規則を推測し、最後に提示される新しい図を同じルールで変換しなければなりません。
ヒントはわずか数例。
正解は一つ。
しかし、推測できる可能性は無数にあります。
この研究では、ARCを人間用に調整した「CogARC」という課題セットが作られました。
75問の問題が用意され、合計260名の参加者が挑戦しました。
重要なのは、単に「正解したかどうか」だけではなく、
・どのくらい時間をかけたか
・どんな編集操作を行ったか
・どのような順序で試行錯誤したか
といった細かな行動ログまで記録された点です。
研究者たちは、人間の思考の“軌跡”を追跡したのです。
人は概してうまく解く。しかし……
まず結果です。
・実験1(40名)では平均正答率 約90%
・実験2(220名)では平均正答率 約80%
人間は概してこの課題をうまく解きます。
しかし、問題ごとの難易度には大きな差がありました。
特に重要だったのは「ルールの複雑さ」です。
研究者は問題を、
・Objectness(物体性)
・Geometry and pattern(幾何・パターン)
・Number and counting(数とカウント)
・Goal-directedness(目的指向性)
というカテゴリーに分類し、さらに複雑さを1〜3段階で評価しました。
その結果、
ルールが複雑になるほど難易度が上昇することが明確に示されました。
一方で、
・グリッドの大きさ
・色の数
・単純な編集回数
といった低次の視覚的要素は、難易度とほとんど関係がありませんでした。
つまり、難しさの正体は「見た目の複雑さ」ではなく、
抽象構造の複雑さだったのです。
考える時間が長い問題ほど難しい
もう一つ興味深いのは「熟考時間(deliberation time)」です。
問題提示から最初の編集操作までの時間を測ると、
・難しい問題ほど熟考時間が長い
・熟考時間と難易度は強い正の相関を示す
という結果になりました。
人は、ルールをつかみにくい問題ほど、
じっと観察し、考え込んでから動き始めます。
そして重要なのは、
編集効率そのもの(どれだけ最短距離で答えに近づいたか)は、
正誤とほとんど関係がなかったことです。
つまり、
考え始める前の推論が勝負を決める。
手を動かす段階の効率は本質ではない。
抽象推論とは、操作の器用さではなく、
仮説形成の質の問題だと示唆されます。
時間が経つと速くなる。しかし賢くはならない
75問を解いていくうちに、参加者はどう変化したでしょうか。
結果は意外でした。
・問題に取りかかるまでの時間は短くなる
・しかし正答率はわずかに低下する
人は、だんだん「速く」なります。
けれど、「上達」しているわけではありません。
個人レベルで見ると、
速くなった人が特に成績を落としたわけでもありません。
研究者はこれを、
・インターフェースへの慣れ
・形式への適応
・軽度の疲労
などが影響している可能性として解釈しています。
重要なのは、
練習によって抽象推論能力そのものが向上した証拠はなかったという点です。
流動性知能(fluid intelligence)は短期訓練では大きく変わらない、
という従来の知見とも整合します。
最大の発見:「間違いが似る」
本研究で最も印象的なのはここです。
間違い方が、驚くほど似ていたのです。
研究者は、5人以上が同じ誤答を出した場合、それを「共通エラー」と定義しました。
その結果、
・多くの問題で特定の誤答が繰り返し出現
・しかもその数は正答数を上回ることもある
・編集の軌跡も似ている
という現象が確認されました。
これは偶然ではありません。
人はランダムに間違っているのではない。
似た仮説を立て、似た方向に誤るのです。
誘導する“見えないバイアス”
研究者はこれを「帰納バイアス(inductive bias)」と関連づけています。
帰納バイアスとは、
限られた情報から効率よく学習するために
あらかじめ備わっている思考の傾向
のことです。
これは欠陥ではありません。
むしろ学習を可能にする前提条件です。
ただし、そのバイアスは時に
もっともらしいが誤った一般化を生み出します。
今回の実験では、
・一部のパターン完成問題で
・正解よりも誤答のほうが多く出るケース
がありました。
つまり人は、
「自然に見える」ルールを優先し、
提示例に完全には一致しない推論を選ぶことがあるのです。
しかしその誤りは一貫しており、
構造をもっていました。
人間らしい推論とは何か
この研究は、人工知能評価にも重要な示唆を与えます。
現在、多くのAIモデルはARC問題で高得点を出せるようになっています。
しかし、
・なぜその答えに至ったのか
・なぜ失敗したのか
を説明できることは稀です。
一方、人間の誤りは解釈可能です。
間違いには“意味”がある。
これは決定的な違いです。
研究者は、
人間のような推論を再現するには
・帰納バイアス
・注意制約
・探索のヒューリスティック
といった認知的制約を組み込む必要があると指摘しています。
正答率を上げるだけでは
人間らしい知性にはならない。
人間の誤り方まで再現できて初めて、
「人間らしい」と言えるのかもしれません。
まとめ
この研究が示したのは、
・抽象推論は高度だが、個人差が大きい
・難しさは構造的複雑さに由来する
・練習ではあまり上達しない
・誤りは偶然ではなく構造的
・人は似たバイアスに導かれて推論する
ということです。
人間の思考は自由奔放ではありません。
見えない枠組みの中で、効率よく世界を理解しようとしています。
その枠組みがあるからこそ、
私たちは少ない例から学べる。
そしてその枠組みがあるからこそ、
似たように間違える。
抽象推論の研究は、
知能の限界を示す研究ではありません。
むしろ、
知能の構造を可視化する研究です。
私たちはどんな仮説空間の中で考えているのか。
どんな可能性を最初から除外しているのか。
その問いは、
AIをどう作るかという問題と同時に、
「人間とは何か」という問いにもつながっています。
間違い方が似ているという事実は、
もしかすると、人間らしさの証拠なのかもしれません。
(出典:arXiv DOI: 10.48550/arXiv.2602.22408)