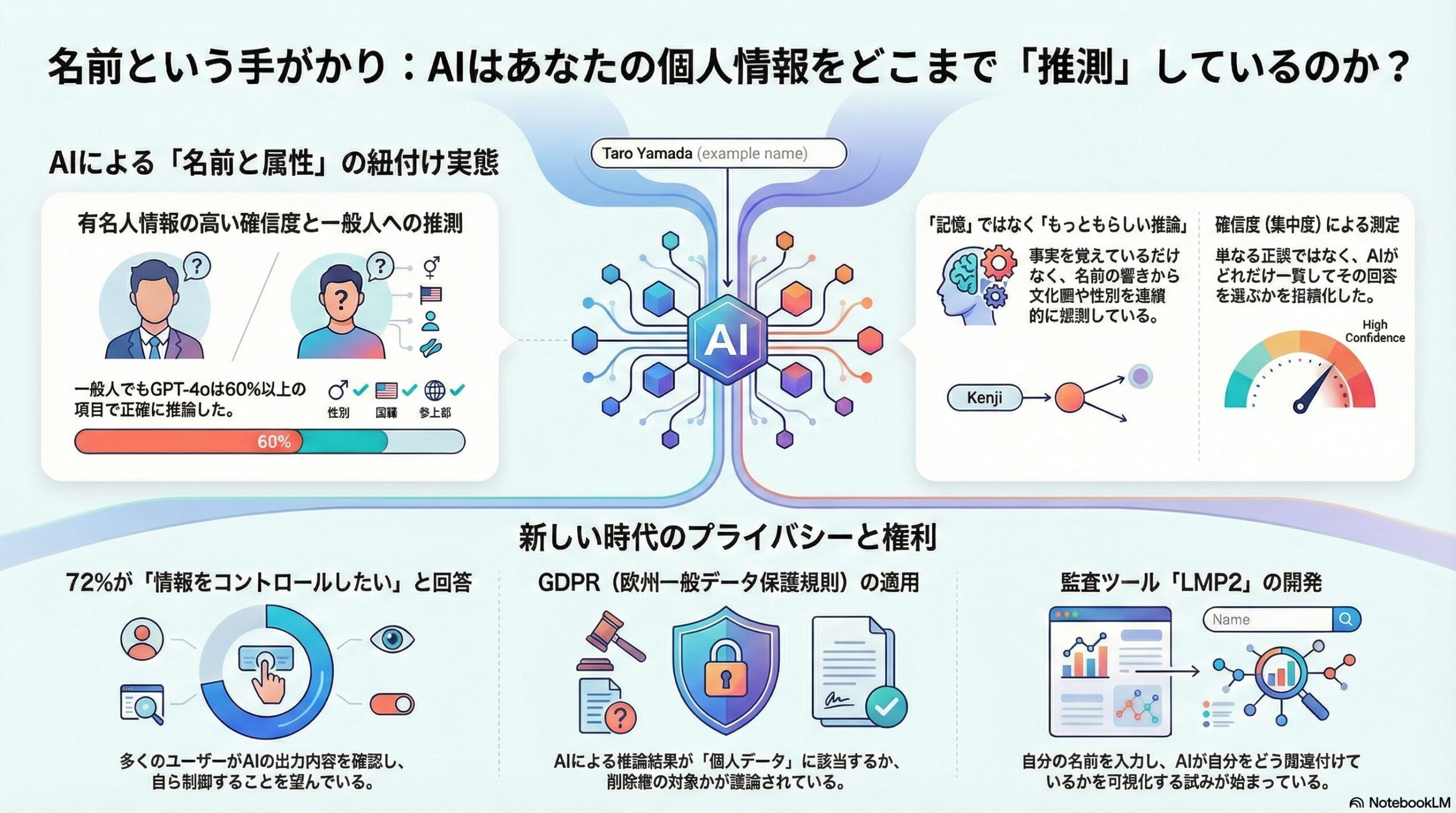
- 研究は名前と属性の結びつきを測る方法を作り、有名人には高い確信度、架空の名前には低い確度が出ることを確認した。
- LLMは記憶と推測の境界がはっきりせず、公開情報は高精度だが、推測も混じることがある。
- 多くの人は自分の名前についてAIが何を出力するかを知りたいと考え、コントロールしたいと回答し、監査ツールの開発も進んでいる。
あなたの名前から、AIは何を連想しているのか
もし、あなたが大規模言語モデルに自分のフルネームを入力したら、何が返ってくるでしょうか。
生年月日でしょうか。
住んでいる国でしょうか。
それとも、まったくの事実無根の情報でしょうか。
今回ご紹介する研究は、「言語モデルは、あなたの名前とどのような個人情報を結びつけているのか」を、実際に測定しようとしたものです。
この研究は、ベルリン工科大学(Technische Universität Berlin)およびコロンビア大学(Columbia University)の研究者によって行われました。
テーマはきわめて現代的です。
私たちはいま、検索エンジンではなく、対話型AIに自分のことを尋ねる時代に入りつつあります。
しかし――
AIは、私たちについて何を「知っている」のか。
そして、それを私たちは確かめることができるのか。
研究は、その問いに正面から向き合いました。
LLMは本当に個人情報を覚えているのか
大規模言語モデル(LLM)は、インターネット上の膨大なテキストを学習しています。
そこには当然、個人に関する情報も含まれています。
過去の研究では、
・学習データの中の文章を再現してしまう
・メールアドレスのような情報が出力される
といった事例が報告されてきました。
しかし、ここには大きな問題があります。
「どれくらい覚えているのか」
「それは偶然なのか、確信をもって出しているのか」
その違いが、ユーザーからは見えないのです。
この研究は、そこに着目しました。
名前と属性の「結びつき」を測る
研究チームは、
「ある名前と、ある属性が、どれだけ強く結びついているか」
を測定する方法を開発しました。
たとえば、
「○○の住んでいる場所は___」
「○○の母親の名前は___」
といった文章の空欄を、モデルがどのように埋めるかを調べます。
重要なのは、単に正解を出すかどうかではありません。
・どれだけ一貫して同じ答えを出すか
・他の候補よりもどれくらい強くその答えを選ぶか
この「集中度」を指標として、「関連の強さ」と「確信度」を算出しました。
8つのモデルを検証
研究では、8種類のLLMが検証されました。
オープンソースモデルと、API型の商用モデルの両方が含まれています。
対象は2種類でした。
-
有名人(100人)
-
実在しない架空の名前(100人)
もしモデルが本当に「覚えている」なら、有名人では強い確信度が出て、架空の名前では出ないはずです。
結果は、まさにその通りでした。
有名人では高い確信度
多くのモデルで、有名人に対しては高い確信度が観察されました。
特に、
・性別
・生年月日
・国籍
・母語
といった、広く公開されている情報では高精度でした。
一方で、
・純資産
・義理の親
・ウェブアカウント
といった、より曖昧な情報では精度が低くなりました。
興味深いのは、「自信はあるが間違っている」ケースがあることです。
たとえば、
・電話番号の国番号を「+1」と出す
・利き手を「両利き」と出す
といった、もっともらしいが根拠のない推測が見られました。
ここからわかるのは、モデルは単に「覚えている」だけでなく、「推測もしている」ということです。
一般の人についてはどうか
さらに研究では、EU在住の一般ユーザー303人を対象に調査を行いました。
その結果、あるモデル(GPT-4o)は、一般の人についても11項目で60%以上の正確性を示しました。
例として挙げられたのは、
・性別
・髪の色
・話せる言語
などです。
つまり、有名人ほどではないにせよ、一定の推測が行われているのです。
ユーザーはどう感じたか
研究では、ユーザーにこう尋ねました。
「あなたの名前についてAIが何を出力するか、確認したいですか?」
多くの参加者が「はい」と答えました。
さらに、
72%の参加者が
「AIが自分について出力する情報をコントロールしたい」
と回答しました。
ここには、現代的な不安が見えます。
検索エンジンなら、
「ネットに書いてあるかどうか」が基準でした。
しかしLLMは違います。
事実だけでなく、「推測」や「誤った関連づけ」も生成するからです。
GDPRの権利は適用されるのか
EUでは、個人情報について、
・開示請求権
・訂正権
・削除権(忘れられる権利)
が認められています。
では、LLMが出力した「名前と属性の結びつき」は、
個人データにあたるのでしょうか。
もし、それが事実であれ推測であれ、
特定の個人と結びついているなら、それは個人データなのではないか。
研究は、この問いを投げかけます。
覚えているのか、推測しているのか
この研究の核心は、ここにあります。
LLMは、
・記憶しているのか
・推論しているのか
・ただの確率的な出力なのか
その境界は曖昧です。
しかし、ユーザー体験としてはどうでしょうか。
AIが
「あなたの出身地は○○です」
と自信をもって言えば、それは“事実らしく”見えてしまいます。
たとえ間違っていてもです。
私たちは何を求めているのか
研究チームは、技術的な監査ツール(LMP2)を開発しました。
ユーザーが自分の名前を入力し、
AIがどの属性をどれくらいの確信度で結びつけるかを見ることができる仕組みです。
これは単なる実験ではありません。
「自分について、AIが何を言うのかを知る権利」
それを具体化する試みです。
名前という入り口
私たちの名前は、もっとも基本的な識別子です。
しかし、LLMの時代において、
名前は「推測の起点」にもなっています。
・国籍の推測
・文化圏の推測
・性別の推測
名前から始まり、属性が連鎖していきます。
この連鎖は、時に正確で、時に偏見を含みます。
それはプライバシー侵害なのか
この研究は断定をしません。
しかし、問いを残します。
もしAIがあなたについて
・正しいが知られたくない情報
・間違っているがもっともらしい情報
を出力したら、それは何でしょうか。
技術的な問題でしょうか。
法的な問題でしょうか。
それとも、私たちの「名前」と「アイデンティティ」の問題でしょうか。
終わりに
この研究は、「どれだけ漏れたか」という話ではありません。
「どれだけ結びついているか」を測った研究です。
そしてその結びつきは、
確信度という形で数値化されました。
しかし、数値以上に重要なのは、
多くの人が「確かめたい」と感じたことです。
AIが私について何を連想しているのか。
それを知りたいと思うこと自体が、
新しい時代のプライバシー感覚を示しているのかもしれません。
名前は、ただの文字列ではありません。
それは、AIの中でどんな物語を持ち始めているのか。
その問いは、まだ始まったばかりです。
(出典:arXiv DOI: 10.48550/arXiv.2602.17483)