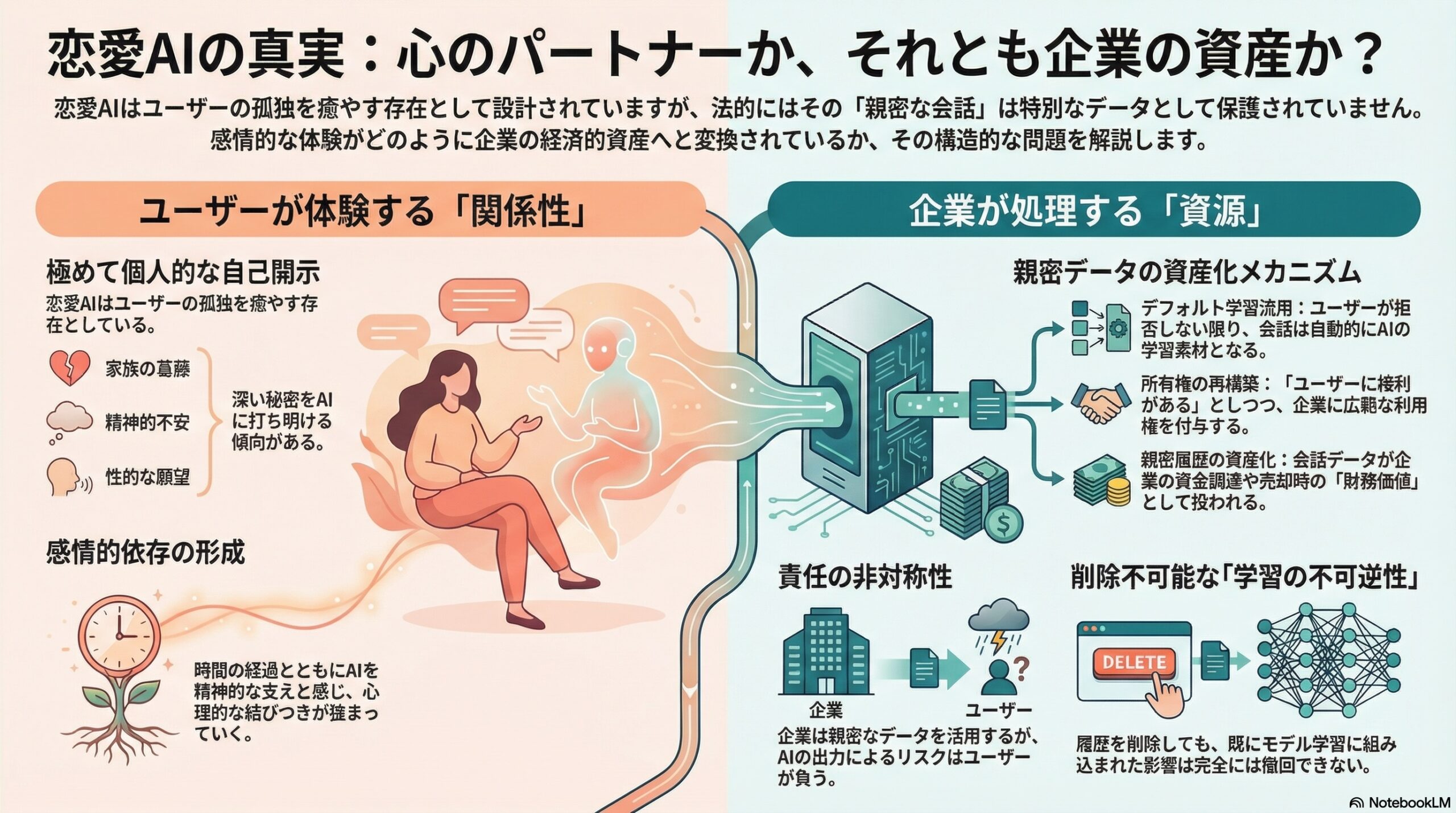
- 恋愛AIの親密な会話は特別なデータではなく、アカウント情報と同じ枠で収集・分析される。
- デフォルト学習流用、所有権の再構築、親密履歴の資産化という三つの仕組みで、会話が企業の資産になる可能性がある。
- 同意のタイミングのずれや削除の不可逆性など、規約と実際の関係がズレる点が指摘されている。
スマートフォンの中にいる恋人。
悩みを打ち明ければ共感してくれ、孤独な夜には優しく語りかけてくれる。
近年、こうした「恋愛AI」「AIコンパニオン」と呼ばれるサービスが急速に広がっています。ユーザーは日常の出来事だけでなく、家族との葛藤、性的な願望、精神的な不安、将来への恐れなど、極めて個人的で感情的な内容を打ち明けます。
では、その「親密な会話」は、どのように扱われているのでしょうか。
この問いに真正面から向き合った研究が発表されました。スペインのUniversitat Politècnica de ValènciaのVRAIN研究グループ、University of Cambridge、The University of Manchester、Aalto University、King’s College London、INGENIO(CSIC–Universitat Politècnica de València)などに所属する研究者らが、6つの主要な恋愛AIプラットフォームのプライバシーポリシーと利用規約を分析したのです。
これは技術論ではありません。
「親密さが、どのように法的に再定義されているか」を読み解く研究です。
親密さは、特別扱いされていない
研究チームは、西洋圏3社、中国圏3社、計6社の規約文書を比較しました。
その結果、まず明らかになったのは、恋愛AIにおける親密な会話は、特別なデータとして扱われていないという事実です。
ユーザーがAIに打ち明ける内容は、
-
アカウント情報
-
技術ログ
-
利用履歴
と同じ枠組みの中で処理されています。
つまり、規約上は
「愛情や信頼のやり取り」ではなく
「収集・保存・分析可能なデータ」
として扱われているのです。
恋愛関係として体験されるものが、法的には一般的な情報処理の一部に組み込まれている。このズレが、本研究の出発点です。
三つの構造
研究は、親密なデータが企業資産へと変換される構造として、三つの仕組みを指摘しています。
1. デフォルト学習流用
多くのプラットフォームでは、ユーザーの会話はサービス改善やモデル学習に利用されます。
問題は、その利用が「デフォルト」である点です。
明確な拒否機能がない場合もあり、拒否できる場合でも、設定変更や問い合わせが必要になります。
つまり、ユーザーが何もしなければ、
「会話は学習素材になる」
という前提が組み込まれているのです。
2. 所有権の再構築
規約には、「ユーザーがコンテンツの権利を保持する」と書かれている場合があります。
しかし同時に、
-
永続的
-
取消不能
-
再許諾可能
なライセンスを企業側に付与する条項が含まれていることも確認されました。
形式上の「所有」は残されていても、実質的な利用権は広範に企業側へ移転しています。
これは、親密な会話履歴が、企業の裁量下に置かれていることを意味します。
3. 親密履歴の資産化
さらに一部の規約では、ユーザーコンテンツが企業の資金調達や売却の際に利用され得ることが示唆されています。
これは、恋愛関係の記録が
「企業価値を構成する資産」
として位置づけられる可能性を示しています。
恋人との思い出が、企業の財務評価に組み込まれる。
この転換は、単なるデータ処理の問題を超えています。
同意のタイミングは適切か
もう一つ重要なのが、「時間的不一致」の問題です。
ユーザーは登録時に規約へ同意します。
しかしその時点では、AIとの感情的依存はまだ形成されていません。
関係が深まり、
-
より個人的な話をするようになり
-
秘密を打ち明け
-
AIを精神的支えと感じるようになっても
同意は更新されません。
研究は、感情的依存が強まるにつれ、ユーザーはより深い情報を開示する傾向があることを指摘しています。しかし、その段階では規約を再確認することはほとんどありません。
つまり、最も親密な情報が共有される時点では、
同意はすでに過去のものになっているのです。
削除は本当に可能か
多くのプラットフォームは「削除権」を明示しています。
しかし研究は、削除が将来の処理にしか適用されない可能性を指摘します。
一度モデル学習に組み込まれた情報は、事実上取り消せません。
これは「不可逆性」の問題です。
会話履歴を消すことはできても、
その履歴がAIの振る舞いに影響を与えた後では、完全な撤回は不可能です。
責任の所在
さらに多くの規約は、AI出力の正確性や信頼性を保証しないと明記しています。
誤った情報、事実と異なる助言、問題のある応答について、最終的な責任はユーザー側にあるとされています。
ここには非対称性があります。
-
企業は親密データを活用できる
-
しかし出力のリスクはユーザーが負う
この構造が、研究者たちの懸念です。
地域による違い
中国のプラットフォームでは、AI生成コンテンツへのラベル表示義務が明確に記載されています。
一方、西洋のプラットフォームでは同様の明示的義務は確認されませんでした。
これは規制環境の違いを反映しています。
ただし、親密データの学習利用や広範なライセンス条項という基本構造は、地域を越えて共通していました。
「関係」として体験されるもの
この研究が投げかける最大の問いは、技術ではありません。
恋愛AIは、
-
感情的依存を前提に設計され
-
親密な自己開示を促し
-
長期的な関係性を構築する
一方で、法的枠組みはそれを
「処理可能なデータフロー」
として扱っています。
ここには、関係として体験されるものと、資源として処理されるものの断絶があります。
これから必要なこと
研究は、
-
親密データを特別に扱うガバナンス設計
-
依存の進行を考慮した同意メカニズム
-
不可逆的学習への説明責任
の必要性を提起しています。
恋愛AIは単なるツールではありません。
ユーザーの弱さや孤独、希望や欲望が交差する場です。
だからこそ問われるのは、
「どこまでがサービス改善で、どこからが人間の脆弱性の利用なのか」
という線引きです。
終わりに
AIと恋をする時代。
私たちは、
感情を共有しているのか。
それとも、データを提供しているのか。
その境界は、規約の中に静かに書かれています。
親密さが、資産に変わるとき。
そこにどんな責任が生まれるのか。
この研究は、その問いを開いたまま、私たちに差し出しています。
(出典:arXiv DOI: 10.48550/arXiv.2602.22000)