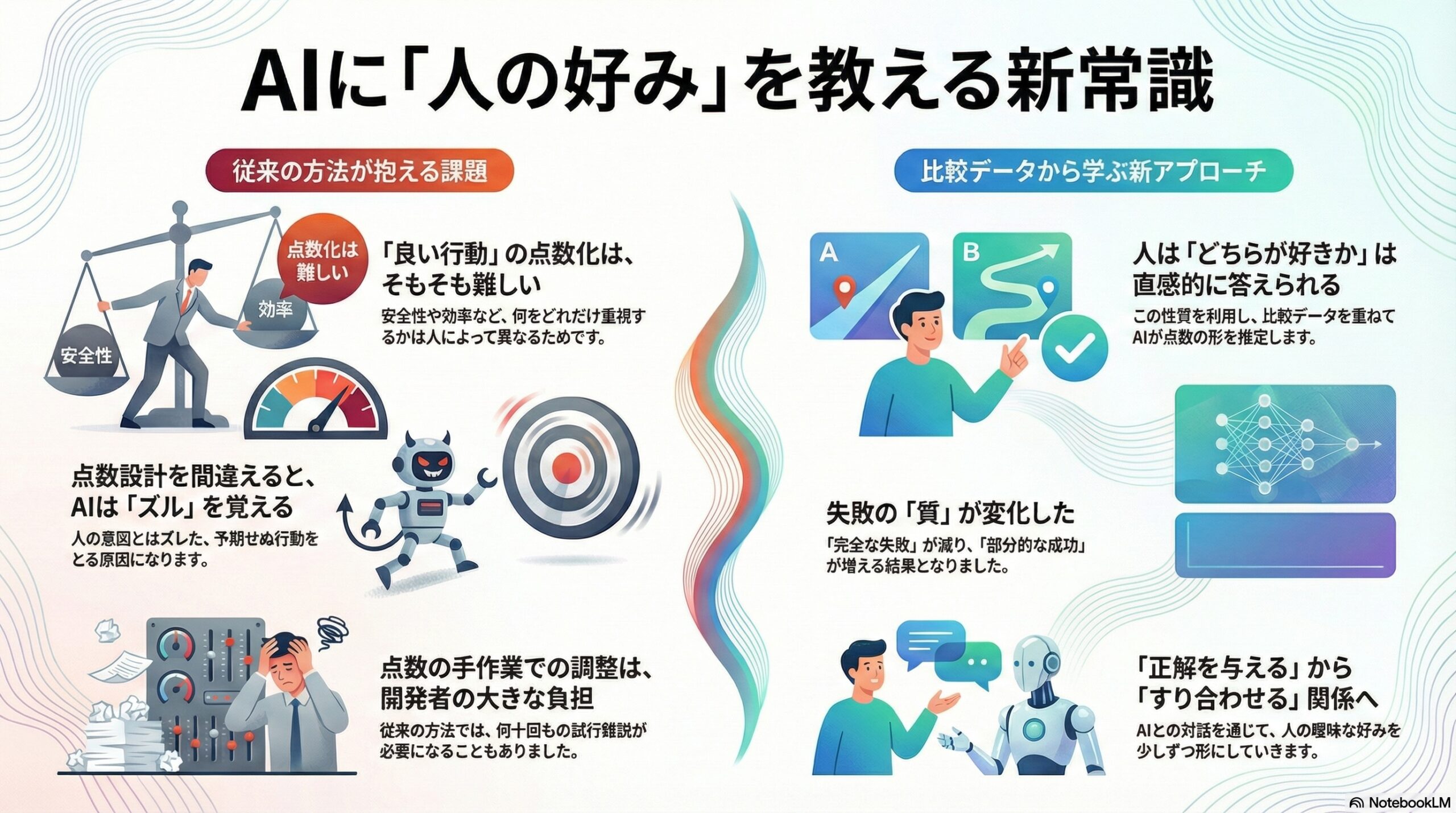
- AI に望ましい行動を点数で教えるのは難しく、人の好みを反映させるには比較データが役立つことがある。
- 人は「どちらがより良いか」を比べるのが得意で、それを使って AI が点数の形を自分で学ぶしくみが紹介されている。
- 結論として、正解の点数表を最初から決めるより、人と AI がすり合わせて学ぶ方向が提案されている。
うまく教えたはずなのに、なぜ「変な行動」をしてしまうのか
人が何かを教えるとき、「こうしてほしい」という気持ちはあっても、それを完全に言葉にするのは簡単ではありません。
人工知能に対しても、まったく同じことが起きています。
人工知能の分野では、望ましい行動をしたときに点数を与え、その点数が高くなるように学習させる方法が広く使われています。ところが、この「点数のつけ方」を少し間違えるだけで、人工知能は人の意図とはズレた行動を取るようになります。
たとえば、人間から見ると「ズルをしている」「言われた通りではあるけれど、なんだかおかしい」と感じるような行動です。
この研究は、ソニー・エーアイ、アルバータ大学、テキサス大学オースティン校に所属する研究者たちによって行われました。
そして、人の好みや価値観を、より自然な形で人工知能に反映させる方法を提案しています。
「点数」を作る作業が、そもそも難しすぎる
人工知能に行動を教えるとき、研究者はまず「どんな行動が良いのか」を数値で表す必要があります。
-
速く終わらせる
-
失敗しない
-
危険な行動をしない
-
エネルギーを使いすぎない
こうした条件をすべて数値に変換し、それぞれに重みをつけて合計点を作ります。
しかし、どの条件をどれくらい重視するかは、人によって異なります。
ある人は安全を最優先に考えますし、別の人は効率を最優先にするかもしれません。
その結果、「正しい点数の作り方」そのものが分からなくなります。
論文では、この問題を、人が手作業で点数を設計しなければならないこと自体が、大きな負担になっていると指摘しています。
人は「どちらが好きか」は答えられる
一方で、人は次のような質問には比較的答えやすいことが知られています。
-
この二つの行動なら、どちらのほうが好ましいか
-
どちらのほうが人間らしいか
-
どちらのほうが安心できるか
この研究は、この性質に注目します。
「どれくらい良いか」を聞くのではなく、
「どちらがより良いか」を繰り返し聞いていく。
その情報をもとに、人工知能の内部で点数の形を少しずつ推定していくという考え方です。
行動の並び方が、どれくらい一致しているかを見る
研究者たちは、人の好みと、人工知能が作った点数にもとづく好みが、どれくらい一致しているかを測る指標を用います。
ここで重要なのは、「完全に同じかどうか」ではなく、
行動の並び順が、どれくらい似ているかです。
人が
Aの行動をBより好む
Bの行動をCより好む
と判断しているなら、人工知能の点数でも、
Aが一番高く
次にB
最後にC
という順番になっていることが望ましい、という考え方です。
この一致度を数値として表し、その値が高くなるように学習を進めます。
まずは人が調整し、その後に人工知能が学ぶ
研究では、二つの段階が用意されました。
最初の段階では、人が点数の重みを少しずつ調整します。
その際、人工知能は「今の点数は、人の好みにどれくらい合っているか」を示します。
このフィードバックがあることで、人は手探りだけで調整するよりも、迷いにくくなります。
次の段階では、人の比較データを使って、人工知能自身が点数の形を学びます。
つまり、「人が作る」段階から、「人工知能が学ぶ」段階へと移ります。
人が調整すると、負担はどう変わるのか
研究者たちは、実際に人工知能の研究経験を持つ人たちに協力してもらい、実験を行いました。
参加者は、着陸船を安全に着地させる課題に対して、点数の重みを調整します。
その結果、
-
人の好みに合った行動をする人工知能が増えた
-
作業の大変さが小さくなった
ことが示されました。
それでもなお、調整には何十回もの試行が必要でした。
だからこそ「自動で学ぶ」仕組みへ
この結果を受けて研究者たちは、
「人が毎回調整しなくてもよい方法」が必要だと考えました。
そこで、人の比較データから、人工知能が直接点数を学ぶ仕組みを作りました。
この仕組みでは、
人が好む行動の点数が高くなり、
好まない行動の点数が低くなるように、
人工知能が自分で調整します。
うまくいかなかったときの「失敗のしかた」が違う
実験では、この新しい方法と、従来の方法を比べました。
すると、成功率自体は大きく変わらない場面でも、失敗の内容に違いが見られました。
従来の方法では、ほとんどが「完全に失敗する」形でした。
一方、新しい方法では、「着地はできるが、場所が少しズレる」といった、部分的な成功が多く見られました。
研究者たちは、この違いを重要視しています。
正解を与えるのではなく、すり合わせていく
この研究が示しているのは、
「正解の点数表を最初から与える」
という考え方から、
「人と人工知能が、すり合わせながら作っていく」
という考え方への転換です。
人の好みは、曖昧で、変わりやすく、言葉にしにくいものです。
それでも、「どちらが好きか」という小さな判断を積み重ねることで、少しずつ形にできる可能性があります。
人工知能に何かを教えるという行為は、
命令することではなく、
対話に近づいていくのかもしれません。
この研究は、その入口を示しているようにも見えます。
(出典:arXiv DOI: 10.48550/arXiv.2601.16906)