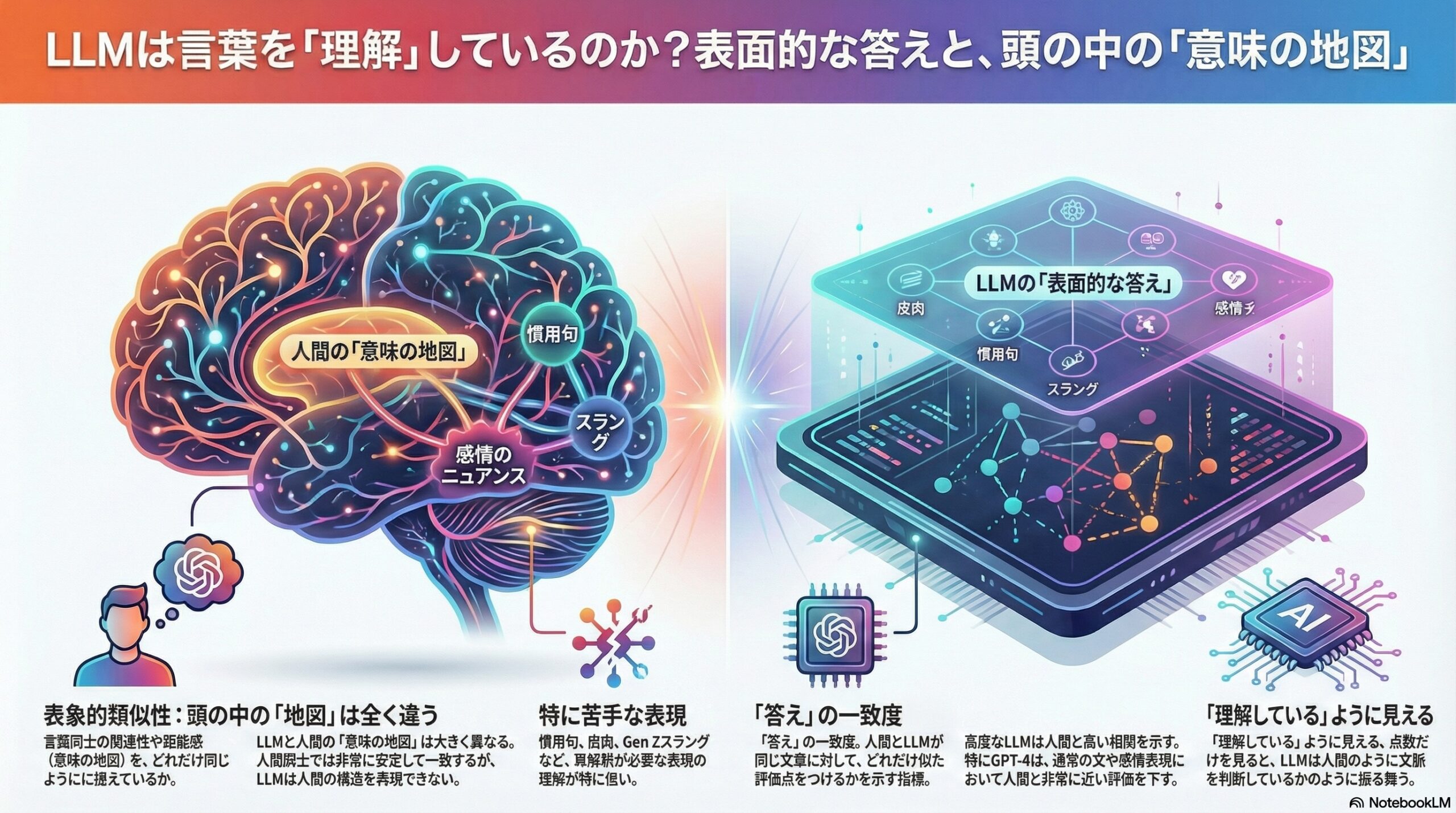
- 表面的にはLLMは人間の評価と近いことがあるが、意味の構造の理解は人間とは異なる可能性がある。
- 感情表現は比較的近いが、慣用表現や皮肉、スラングでは意味の距離感が大きくずれる。
- プロンプトを厳しくしても内部の意味構造の類似性は大きく改善せず、意味を捉える学習が不足している可能性が指摘されている。
表面的な一致と、頭の中の構造のずれ
私たちは日常の中で、言葉をそのままの意味ではなく、文脈や空気を読み取りながら理解しています。
「それ、最高だね」という一言が、本当に称賛なのか、それとも皮肉なのかは、語彙そのものよりも状況や関係性に左右されます。
では、大規模言語モデル(LLM)は、こうした人間特有の言葉の理解にどこまで近づいているのでしょうか。
この問いに対して、本研究は「人間と同じ答えを出しているか」だけでなく、「言葉同士の意味関係を、どのような構造で捉えているか」という、より深いレベルから検討しています。
見かけの正解と、内側の理解は同じではない
これまでの研究では、LLMが人間とよく似た判断を下す場面が数多く報告されてきました。
皮肉やユーモアを含む文に対しても、それらしい評価を返すことがあり、一見すると「理解している」ように見えます。
しかし本研究の著者たちは、ここに重要な疑問を投げかけます。
同じ点数をつけているからといって、同じ意味の理解に基づいているとは限らないのではないか、という疑問です。
たとえば、二つの文章が「ポジティブ」という点では似ていても、「皮肉」「感情」「社会的含意」といった別の側面では大きく異なることがあります。
単純な平均点や相関だけでは、こうした意味の構造そのものは見えてきません。
表面的類似性と、表象的類似性
そこで本研究では、二つの異なるレベルで人間とLLMを比較しています。
一つ目は表面的類似性です。
これは、人間とLLMが、同じ文章に対してどれくらい似た点数をつけたかを相関で見る方法です。
二つ目が、本研究の中心となる表象的類似性です。
ここでは、文章同士の「意味的な距離」に注目します。
複数の質問に対する評価の組み合わせを使い、
「この文章とあの文章は、どれくらい似たものとして扱われているか」
という関係構造そのものを比較します。
この手法は、表面的な正解・不正解ではなく、
意味が頭の中でどのような地図として配置されているかを見るための分析です。
実験の設計
研究では、240文の短い対話文が用意されました。
内容は次の6種類に分類されています。
-
通常の文(コンベンショナル)
-
慣用表現(イディオム)
-
感情表現
-
ユーモア
-
皮肉
-
Gen Zスラング
それぞれに「意味のある文」と、「構造は似ているが意味が破綻した文」が含まれています。
これらの文に対して、人間の参加者と4種類のLLM(GPT-4、Gemma、Mistral、Llama)が、
「皮肉に聞こえるか」「ポジティブか」「不快か」など40項目の質問に10段階で評価を行いました。
人間はアメリカの大学生211名、
LLMはすべてゼロショット条件で同一の課題に取り組んでいます。
表面的には、かなり人間に近い
まず表面的類似性を見ると、特にGPT-4は、人間の評価と高い相関を示しました。
普通の文や感情表現では、かなり人間に近い判断をしていることが確認されます。
一方で、皮肉、ユーモア、スラングといった領域では、
どのモデルでも相関が下がり、とくに小規模なモデルでは差が大きくなりました。
それでも、「点数だけ」を見る限り、
LLMは人間にそれなりに近い判断をしているように見えます。
しかし、意味の配置は大きく違っていた
ところが、表象的類似性の分析では、状況が一変します。
人間同士を二つのグループに分けて比較すると、
意味の構造は非常に安定しており、高い一致が見られました。
これは、人間同士が「どの文が似ていて、どの文が違うか」を、かなり共通の感覚で捉えていることを示しています。
それに対して、LLMと人間の比較では、
表面的な一致ほど高い表象的類似性は見られませんでした。
とくに、イディオム、皮肉、Gen Zスラングでは、
人間が感じている意味の距離関係を、LLMがうまく再現できていないことが明確になります。
GPT-4は最も人間に近い結果を示しましたが、それでも人間同士の一致度には届いていません。
感情表現と慣用表現の違い
興味深い点として、感情表現は比較的、人間とLLMの表象が近い傾向にありました。
これは、感情が語彙や描写として明示されやすいからだと論文では示唆されています。
一方、慣用表現や皮肉は、
言葉の字面からは意味が決まらず、再解釈が必要になります。
この再解釈の部分で、LLMは表層的なパターンに依存し、
人間のような意味の飛躍や文脈依存の理解を安定して行えていないことが、
表象的類似性の低さとして表れていました。
プロンプトを工夫しても、構造は変わらない
研究では、指示文をより厳密にした第二の実験も行われています。
その結果、点数の一致度はやや改善しました。
しかし、意味構造そのものの類似性は、人間同士の水準には達しませんでした。
これは、プロンプト調整で振る舞いは変えられても、意味の内部構造までは簡単に変わらないことを示しています。
何が欠けているのか
本研究は、LLMが失敗している理由を単純に「文脈が足りないから」とは結論づけていません。
同じ文脈なし条件で評価されているにもかかわらず、人間同士では安定した構造が見られるからです。
むしろ、
社会的・語用論的な意味を、安定した形で内部に配置する学習そのものが不足している
可能性が示唆されています。
表面的に似ているからこそ、見えにくい違い
この研究が示しているのは、
「LLMは意味を理解していない」と単純に否定する話ではありません。
むしろ、
人間に似た答えを出せるようになったからこそ、
その内側の違いを精密に見る必要がある
という問題提起です。
言葉の意味は、単なる点数や正誤ではなく、
他の言葉との関係の中で形づくられています。
LLMは、その地図を部分的には共有しているものの、
人間と同じ構造を持っているわけではない。
本研究は、そのずれを、初めて体系的に示した研究の一つと言えます。
そして同時に、
「意味をわかる」とは何なのか、
私たち自身に問い返してくる研究でもあります。
(出典:arXiv DOI: 10.48550/arXiv.2601.09041)