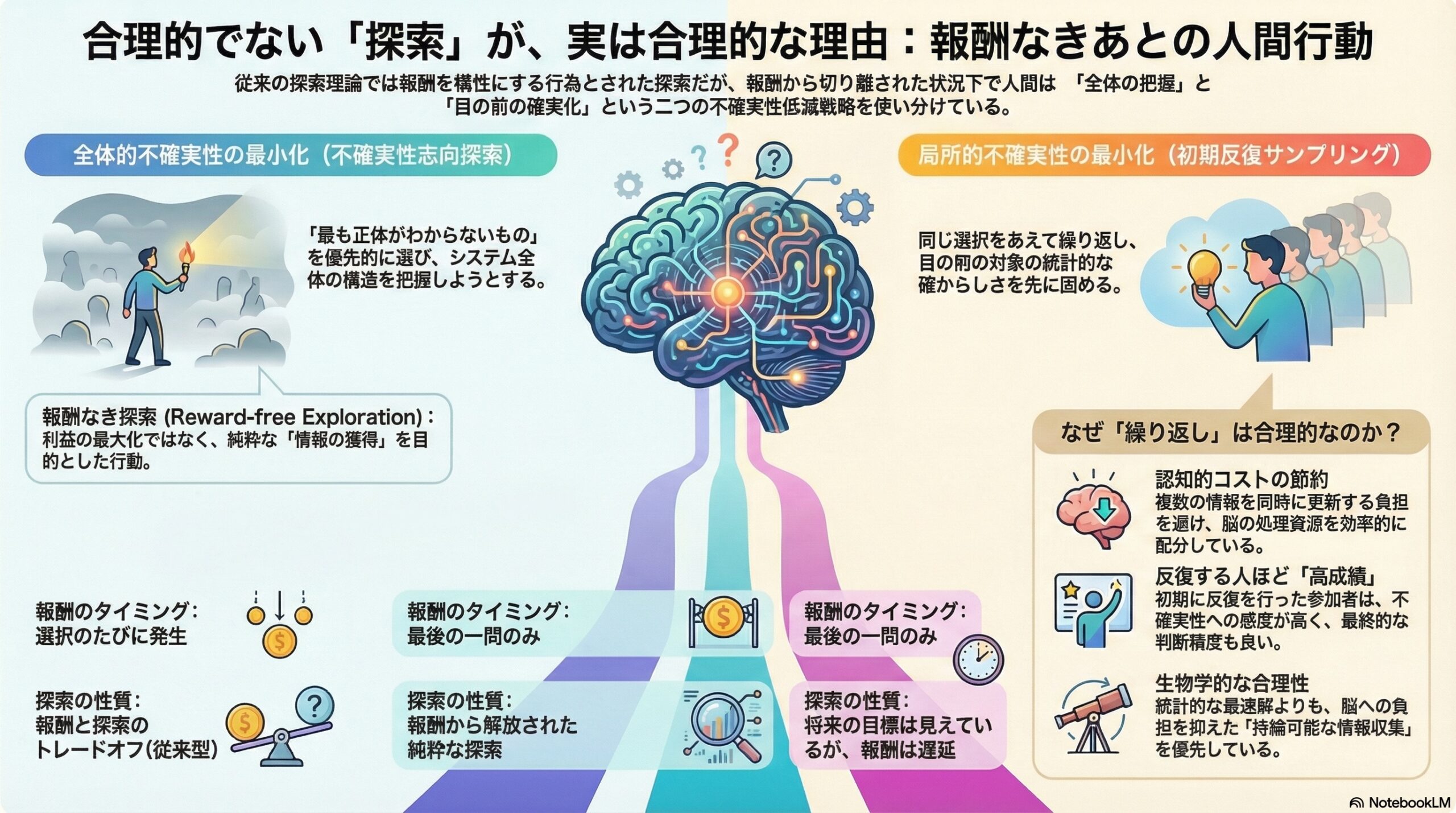
- 報酬を完全になくすと、人は不確実さを減らすための探索でも「全体を見る探索」と「同じ選択を繰り返す局所探索」の両方を使うことが分かった。
- 不確実性を重視する directed exploration(全体を減らす探し方)と、初期は同じ選択を繰り返す閾値戦略(局所を固める探し方)が同時に働く。
- 探索は報酬のトレードオフだけでなく、情報の集め方や認知コストの善し悪しにも影響されると示された。
報酬が消えたとき、人はどう探索するのか
――「最も不確実なものを選ぶ」と「同じものを繰り返す」のあいだ
私たちは日々、「選ぶ」という行為を繰り返しています。
いつもの道を通るか、知らない道を試すか。
同じ店に入るか、新しい店をのぞいてみるか。
このとき私たちは、どのように「探索」しているのでしょうか。
フランスのフランス国立保健医学研究所(Inserm)およびエコール・ノルマル・シュペリウール(École Normale Supérieure, Université PSL)、フランス国立科学研究センター(CNRS)ジャン・ニコ研究所の研究チームは、「報酬から完全に切り離された探索」を実験室で再現する課題を設計し、人間の探索のかたちを詳細に調べました。
その結果、報酬をめぐるジレンマが消えたとき、人間の探索には二つの相反する力が働くことが明らかになりました。
ひとつは「いま選んでいるものを繰り返す」力。
もうひとつは「もっとも不確実なものを選ぶ」力。
一見すると矛盾するこの二つは、実は同じ「不確実性を減らす」という目的のもとで動いています。ただし、その向きが違うのです。
探索は本当に「報酬とのトレードオフ」なのか
従来、探索は「探索か活用か」という対立構造で研究されてきました。
いわゆる「マルチアームド・バンディット課題」です。
この課題では、複数の選択肢から順番に選び、報酬を最大化することが求められます。知らない選択肢を試せば情報は得られますが、すでに良いとわかっている選択肢を選べば確実な報酬が得られます。
つまり探索は常に「報酬を犠牲にする行為」として設計されていました。
しかし、現実の私たちの行動は必ずしもそうではありません。
レストランのレビューを読むとき、私たちはその瞬間に報酬を失うわけではありません。
新しい街で道を確認するときも、すぐに損をするわけではありません。
探索が「報酬と競合しない」状況も多いのです。
研究チームは、この点に注目しました。
探索そのものを、報酬から完全に切り離したらどうなるのか。
色のバンディット課題という工夫
研究では、2つの選択肢から順番に選ぶ課題が用いられました。
ただし、通常のポイントや金銭報酬はありません。
代わりに、選択肢を選ぶと「青寄り」または「オレンジ寄り」の色の図形が提示されます。各選択肢は、青が出やすい袋か、オレンジが出やすい袋かのどちらかに対応しています。
重要なのは、色そのものには価値がないことです。
この課題には三つの条件がありました。
-
MATCH条件
特定の色を目標として与えられ、その色に一致する結果を出すことがその都度報酬になる。 -
GUESS条件
色の対応は最後まで知らされず、最後の一問でどちらの袋がどの色だったかを答える。途中の選択は報酬に直接影響しない。 -
FIND条件
目標色は最初に提示されるが、報酬は最後の一回の判断のみ。途中では得点は発生しない。
MATCHは典型的な「探索と報酬のトレードオフ」状況。
GUESSは「報酬も将来価値もいったん棚上げされた探索」。
FINDは「報酬は遅れるが、将来価値は見えている」状況です。
この設計により、探索が報酬からどの程度独立しているかが検討できました。
不確実なものを選ぶ ――「全体」を減らす探索
結果のひとつは明確でした。
報酬が即時に与えられない条件(GUESSやFIND)では、人はより「不確実な選択肢」を選ぶ傾向を示しました。
ここでの不確実性とは、「どちらの色の袋かわからない度合い」です。
これが高い選択肢を優先的に選ぶ行動は、「不確実性志向探索(directed exploration)」と呼ばれます。
これは理論的にも合理的です。
最後の判断で正しく答えるためには、両方の選択肢の情報をできるだけ均等に集める必要があるからです。
研究では、モデル化によってこの傾向を定量化しています。
不確実性への感度(βunc)というパラメータが、GUESSやFIND条件で有意に高くなりました。
つまり、人は報酬から解放されると、「どちらがわからないか」を積極的に狙いにいくのです。
これは「全体の不確実性」を減らす探索と言えます。
それでも人は繰り返す ――「局所」を減らす探索
ところが、もうひとつの特徴がありました。
GUESS条件では、各シークエンスの初期において、参加者は同じ選択肢を何度も続けて選ぶ傾向を示しました。
最初に左を選んだら、しばらく左を繰り返す。
ある程度情報が集まったあとで、右に移る。
これは、常に最も不確実な選択肢を選ぶ理想的な戦略とは異なります。
むしろ一時的に全体の情報収集効率を落とす行動です。
研究チームはこれを「初期反復サンプリング」としてモデル化しました。
一定量の証拠(θ)に達するまで、同じ選択肢を繰り返す閾値戦略です。
興味深いのは、この行動が報酬が遅延している条件でのみ顕著だったことです。
MATCH条件では、ほとんど見られませんでした。
これは「局所的な不確実性の最小化」と解釈されます。
いま選んでいる選択肢の統計をしっかり固めてから次へ行く。
全体よりも、まず目の前のひとつを確実にする。
そんな探索です。
認知的コストという見えない制約
なぜ、わざわざ非効率な反復をするのでしょうか。
研究は、ここに「認知的コスト」の存在を示唆しています。
常に最も不確実な選択肢を選び続けるには、両方の選択肢の情報を同時に更新し続ける必要があります。これは認知的に負担がかかります。
一方、同じ選択肢を連続して選べば、更新対象はひとつで済みます。
切り替えコストも下がります。
つまり、反復は「情報効率」では劣るかもしれませんが、「認知効率」では優れている可能性があるのです。
研究では、初期反復を示した参加者ほど、
・不確実性への感度が高く
・目標色への感度も高く
・最終成績も良い
という正の相関が確認されました。
反復は単なる惰性や注意不足ではありません。
むしろ積極的な戦略の一部だったのです。
局所と全体のせめぎ合い
この研究の核心はここにあります。
人間の探索には、
-
局所的不確実性最小化
いま選んでいる選択肢を繰り返して精度を高める -
全体的不確実性最小化
もっとも不確実な選択肢を選んで全体構造を把握する
という二つの圧力が同時に働いている。
そしてこのせめぎ合いは、「探索と報酬のジレンマ」状況では見えにくい。
報酬が前面に出ると、探索はすぐに活用に回収されてしまいます。
しかし報酬が消えると、探索そのものの構造が露わになります。
探索は単に「どれが得か」を探す行為ではありません。
「どうやって情報を集めるか」という、より根源的な問題なのです。
探索をどう理解するべきか
この研究は、探索研究がこれまで「探索と活用のバランス」に焦点を当てすぎてきた可能性を示唆しています。
私たちは探索そのものを見ているつもりで、
実は「報酬の重みづけ」を見ていただけかもしれない。
報酬を取り除いたとき、
人間はなお探索する。
そしてそこには、局所と全体のあいだの静かな緊張が存在する。
情報を効率よく集めること。
しかし認知資源も節約すること。
合理性とは、必ずしも「統計的最適」と一致しません。
むしろ「生物として持続可能かどうか」が鍵なのかもしれません。
終わりに
探索が報酬から解放されたとき、人は二つの方向に引かれます。
ひとつは広く全体を見る衝動。
もうひとつは目の前を深く掘る衝動。
この二つは矛盾しているようでいて、
どちらも「わからなさ」を減らそうとする行為です。
私たちは、常に最適な探索をしているわけではありません。
しかし、その不完全さの中にこそ、人間らしい知性の輪郭があるのかもしれません。
探索とは、報酬を超えた営みである。
この研究は、そのことを静かに示しています。
(出典:nature communications DOI: 10.1038/s41467-026-68639-2)